Семантический анализ текста istio
Содержание:
Тонкости создания ТЗ для сео-текста
Перед составлением технического задания нужно подготовить бриф. После определения основных целей текста составляется список требований для копирайтера. Готовый материал должен пройти проверку и после этого может размещаться на сайте. Для защиты текста от плагиата можно воспользоваться сервисом «Яндекс.Вебмастер».
Составление брифа
Текст может быть построен различными методами в зависимости от целей заказчика.
Перед работой нужно определиться:
- с целью текста;
- с действиями, на которые пользователь будет стимулирован после прочтения;
- с целевой аудиторией;
- с ключевыми запросами для страницы сайта.
С учетом указанных пунктов изменится стилистика подачи информации. Копирайтер при необходимости должен получить сведения о специфике товара или бизнеса, который требуется представить в максимально выгодном свете.
https://youtube.com/watch?v=y-i7HRoYJlQ
Анализ текстов от конкурентов: как это сделать
Получить информацию о текстах конкурентов можно в поисковых системах. Ссылки на их страницы появляются первыми в выдаче. Достаточно скопировать контент и воспользоваться специализированными сервисами.
Данные о семантическом ядре покажут использованные ключи. Показатели тошноты, воды и объема используются как ориентир для нового технического задания по тексту сходной тематики.
Определение оптимального объема
Содержимое страницы должно решать проблему пользователя.
Для магазинов это касается сведений:
- о товаре;
- о механизме покупки;
- о преимуществах сотрудничества с данным продавцом.
Из информационных статей посетитель страницы должен получить интересующие его данные. Ориентиром для объема могут служить материалы конкурентов.
Поиск актуальных ключей
Важно собирать ключи, думая с позиции представителя целевой аудитории. Пользователи часто используют сленговые выражения, сокращения слов или полные названия товара для запроса в поисковой строке
Выбор менее популярных фраз может стать хорошим решением для молодых сайтов с небольшой аудиторией.
Структурирование будущего текста
Во время составления ТЗ необходимо задать структуру текста.
Оформленный материал должен иметь:
- Заголовок, указывающий на тему контента.
- Лид — короткое вступление для привлечения внимания посетителя страницы.
- Основную часть с последовательным раскрытием темы.
- Заключение с призывом к действию либо краткими выводами.
Центральная часть может быть разделена на разделы и подразделы. Их содержание зависит от вида запроса (коммерческий, информационный).
Финальная оптимизация статьи
После завершения работы над текстом нужно провести его оптимизацию. Для этого следует проверить структуру заголовков H1-H6 и при необходимости скорректировать их. Роботы Google считают материал полезным при объеме 700 символов и более, а для механизмов «Яндекса» точкой отсчета является показатель в 3000 знаков.
Затем проверяют разбивку абзацев и частоту ключей. Плотность последних рекомендуется поддерживать на уровне 4-6 повторов на 300 слов. В статье должны быть вводная и заключительная части.
Проведение Сео-оптимизации статьи.
Посев (продвижение) статьи
Понятие посева статьи подразумевает привлечение посетителей из нескольких источников.
Основные каналы для начального информирования интернет-пользователей:
- соцсети;
- открытые каналы в мессенджерах;
- форумы и тематические порталы;
- веб-сайты вопросов и ответов — toster.ru, answersall.ru, otvet.i.ua и т.п.;
- YouTube — публикация видео по тематике созданной статьи;
- рассылка email-сообщений и push-уведомлений по базе подписчиков сайта.
Использование нескольких каналов параллельно позволит привлечь максимальное внимание к публикации. Для коммерческих сайтов стоит дополнительно использовать рекламу
Всегда ли нужен анализ текста для продвижения страницы
Дело в том, что проработка текстовых факторов ранжирования подразумевает все зоны документа, среди которых – тайтл, метаописание, заголовки, навигация, «хлебные крошки», интерактивные элементы страницы, товарные карточки, отдельные фрагменты текста и т.п. Текст в рамках SEO – это не статья, и не SEO-«портянка». Это весь текстовый контент страницы в совокупности
Однако имейте в виду, некоторые зоны контента важнее других, и эта важность меняется со временем, а также в зависимости от типа документа, его задачи и конкретной поисковой системы
Попробуйте угадать, чему посвящена страница по облаку частотности слов. Подсказка: это не самые заметные ключи.
Важный момент: Яндекс и Google оценивают качество текста по-разному. Чтобы страница получила высокие позиции в обеих системах, надо использовать гибридные технологии. Если немного обобщить, то если речь идёт о коммерческой страничке, для Яндекса наличие SEO-текста не просто неполезно, оно скорее вредно, если только не содержит необходимую для посетителя информацию. Google же исповедует принцип «комплексного ответа». В его рамках страница вполне может быть оптимизирована и под информационные, и под коммерческие запросы.
Особые сервисы и программы для скачивания
Кроме вышеописанных сайтов, при написании текстов стоит пользоваться еще несколькими.
«Главред»
«Главред» используется для определения качества текста, написанного в информационном стиле. Достоинства программы:
- Работает в онлайн-режиме.
- Сканирование занимает 5 секунд.
- Помогает разобраться в работе с контентом, т.к. есть объяснения к каждой ошибке.
- Поясняет, как нужно заменять выделенные слова.
- Доступно редактирование в окне.
«Главред» — онлайн-сервис проверки текста.
Недостатки:
- Не понимает контекст, из-за чего занижает оценку только за употребление некоторых слов, даже если они использованы уместно.
- Орфографию не проверяет.
- Игнорирует предложения и слова в кавычках, считая их цитатой.
- Опечатки мешают программе проанализировать текст.
«Орфограммка»
Данный сервис используется для автоматического поиска орфографических, стилистических, пунктуационных ошибок и т.д. Работа сайта основана на искусственном интеллекте, умеющем обнаруживать несоответствия правилам русского языка с учетом контекста. При этом к каждой ошибке есть объяснение и ссылка на правило. Внутренний словарь имеет 5 млн лексем. В тех случаях, когда автор использует неизвестное слово, система попросит его пополнить базу данных.
Во вкладке с документами копирайтер может посмотреть статистику всех проверенных материалов. В ней отображаются:
- Индекс удобочитаемости, т.е. сложность восприятия текста.
- Индекс туманности, т.е. уровень образования, необходимый читателю, чтобы понять смысл высказываний.
- Статистика частотности словоформ.
«Орфограммка» используется для поиска ошибок в тексте.
Недостатки сервиса:
- Необходимость создания «Личного кабинета».
- Платная подписка. Для школьников есть скидка в 50%, а для учителей пользование сервисом бесплатное.
Преимущества:
- Есть проверки всех видов ошибок.
- Можно загрузить текст в формате «Ворд» или вставить его в специальное окно.
- Есть анализ текста по пунктам удобочитаемость и туманность.
Test-the-text
Сайт исследует соответствие материала информационному стилю, в котором пишутся описания товаров, инструкции, новости и т.д. Цель таких статей — донести информацию до человека с любым образованием. В них не должно быть «водных» слов, эмоций и личного мнения. Проверка на информативность важна не только для копирайтеров, пишущих описания гаджетов, сайтов, продуктов и т.п., но и для веб-дизайнеров. Это связано с тем, что любая часть сайта должна быть понятна пользователю.
Сервис был создан Анатолием Лариным, поэтому здесь есть не только программа, но и рекомендации по работе с текстовыми документами от создателя.
Vaal (анализирует эмоциональность)
Сайт помогает определить частотность эмоционально окрашенных слов. После завершения анализа они подчеркиваются. Также система может:
- Оценить воздействие фонетической составляющей на человека.
- Подобрать слова с выбранными фоносемантическими параметрами.
- Задать характеристики сканирования, чтобы упростить процесс редактуры.
- Оценить звуко-цветовые параметры.
- Производить эмоционально-лексический анализ текстов.
Функций у данного сервиса много, однако он редко используется, т.к. в информационных статьях эмоциональности не должно быть.
Процесс работы
Для того чтобы получить доступ к максимальному функционалу сервиса, необходимо зарегистрироваться на сайте. Сразу после регистрации вам станет доступна проверка на уникальность 20 текстов в сутки объемом до 10 000 символов. Для незарегистрированных пользователей проверить можно всего 5 текстов в сутки объемом до 3 000 символов. Для использования услуг в больших объемах следует подключить один из шести предложенных тарифных планов для регулярной и ручной работы.
.png)
Поскольку антиплагиат-проверка осуществляется на сайте компании, нет необходимости ожидать свою очередь, как иногда бывает на подобных сайтах. Сам процесс анализа на уникальность потребует от вас наличия текста, который необходимо вставить в специальное поле и проверить.
.png)
Если контент уже размещен на каком-то сайте, но у вас возникла необходимость его контроля, тогда во избежание выдачи 0% уникальности, можно воспользоваться настройкой «Игнорировать». Это позволит анализировать уникальность текста без учета определенного сайта. Для этого нужно указать только его домен или, например, адрес блога.
.png)
Интерфейс Content Watch создан с сохранением концепции простоты и наглядности. Поэтому в поле зрения всегда только важная информация. Над полем с проверяемым текстом указывается число введенных символов. Это очень полезно, особенно тем пользователям, которые не являются зарегистрированными на сайте. Максимально допустимое количество символов за один раз составляет всего три тысячи. Пока это число выделено зеленым, текст — в допустимых количественных рамках. Если красным, необходимо его сократить или, наоборот, увеличить, иначе проверка не будет произведена.
.png)
Если у вас возникла необходимость анализа контента на всем сайте сразу, тогда вы сможете воспользоваться целым набором удобных инструментов:
- Проверкой отдельной страницы вебсайта, что потребует от вас ведения ее адреса. После этого сервис получит все содержимое страницы, очистит его от структурных элементов и проверит.
- Проверкой перечня страниц. Для этого нужно указать их адреса. Сервис проверит их и выдаст результаты в формате списка с возможностью просмотра всех подробностей проведенного анализа.
- Проверкой страниц вашего ресурса по маске, подразумевающей двухэтапную проверку, где вначале потребуется указать домен сайта и его раздел, правила, которым адреса страниц должны соответствовать. Сервис ищет карту сайта и осуществляет поиск максимального числа соответствующих правилам страниц. После этого формируется их список, который можно отправить на анализ. Вторым этапом является контроль на уникальность.
Защита сайта от несанкционированного копирования контента является дополнительной услугой компании. Воспользоваться ею можно, осуществив автоматическую проверку веб-страниц. После этого на своем сайте нужно разместить сообщение о том, что при цитировании вашего контента вы требуете размещать активную ссылку на него, что сделает из плагиата естественные ссылки.
Также пакет защиты позволит рассылать письма владельцам тех сайтов, на которых вы нашли свой контент. Система будет формировать для вас отчеты, при помощи которых вы сможете выявлять плагиат и принимать меры по его предотвращению. Преимуществом, которое подчеркивают отзывы, является автоматический контроль контента, экономящий ваше время.
Для автоматического антиплагиат-сканирования контента можно использоваться API-интерфейс сервиса. Для этого не нужно подписываться на обслуживание — достаточно просто пополнить свой баланс. Стоимость одной проверки начинается с 25 копеек.
Текст для проверки не должен превышать 15 тысяч символов. Если вы будете использовать услугу в больших объемах, компания с радостью предоставит вам скидку от 20 до 60%.
Приблизительно распределение скидок выглядит так:
- от 3 000 запросов на проверку за месяц — 20%;
- от 6 000 запросов — 40%;
- от 10 000 запросов — 60%.
Чтобы получить скидку, необходимо обратиться в службу технической поддержки сервиса. Оплату услуг компании можно производить путем пополнения баланса через электронные платежные системы.
Преимущества content-watch.ru:
- Простой интерфейс.
- Недорогие тарифные планы.
- Большой выбор способов оплаты.
- Быстрая регистрация.
- «Молниеносный» контроль уникальности.
Недостатки:
- Жесткие ограничения для проверки на бесплатной основе.
- Неудобство проверки большого текста.
- Не предусмотрена возможность правки текстов непосредственно в окне проверки.
Content-Watch представляет собой сервис, который позволяет быстро проверить уникальность текста онлайн. Имеется возможность осуществить проверку как текста, так и целого документа.
Как проверить LSI
Так как алгоритмы поисковых систем постоянно усложняются и становятся более жесткими, продвигать сайты становится все сложнее. Относительно новое понятие LSI – значит, что использовать привычные конструкции «купить Москва» и публиковать откровенно коммерческий контент уже не результативно.
Главное требование к текстам, которое «предъявляют» поисковики – это информативность для читателей и читабельность. Для этого и нужны LSI – слова, которые, отвечают релевантности запроса, но при этом не выглядят как очевидно коммерческий и продающий текст. То есть, вписаны органично и по смыслу.
Serpstat
Крупнейший сервис, который дает полную оценку LSI параметров сайта. Есть бесплатный тестовый период. Однако для постоянного использования нужно купить пакет выбранных услуг. Но оно однозначно того стоит: множество инструментов для аналитики сайта, понимание которой повышает продажи, конверсии и позицию сайта в таких поисковиках как Google и Яндекс.

Megaindex
Еще один сервис, где можно проверить LSI показатели. Доступ можно получить только после регистрации. Есть бесплатный тариф, однако возможности на нем сильно ограничены и, если нужно использовать данный инструмент достаточно часто, — лучше приобрести платный пакет услуг.
«Арсенкин»
«Арсенкин» — это все SEO инструменты в одном месте. Что может «Арсенкин»:
- переоптимизация;
- парсинг;
- проверка ИКС;
- кластеризация запросов.
Есть бесплатный тариф с конкретным количеством проверок и тарифы платные с дополнительными функциями и возможностями.
Пример семантического анализа текста
Давайте разберем показатели на примере анализа текста по семантическому анализатору от Адвего. Первые несколько строк — количество знаков с пробелами и без, количество слов, уникальных и значимых слов — не так важны. Важны следующие показатели:
- Вода — 67,7%;
- Классическая тошнота документа — 4,12%;
- Академическая тошнота документа — 8,7%;
- Семантическое ядро;
- Частота слов в семантическом ядре.
Давайте остановимся на каждом показателе подробнее.
Водность текста
Семантический анализатор Адвего показывает самую высокую водность — на других сервисах при проверке нашего текста она 44% и 5%. Показатель водности — это соотношение незначимых слов к общему количеству слов. Чем больше в тексте стоп-слов, не несущих смысловой нагрузки, тем выше процент воды.
Слова, которые сервис считает «водой», выводятся в отдельной таблице «Стоп-слова». Чаще всего в нее попадают предлоги и местоимения. Кстати, нормальный показатель, упомянутый в описании семантического анализа по Адвего — 55-75%. Значит, в нашем тексте уровень воды нормальный.
Это интересно: Как повысить уникальность текста
Классическая тошнота документа
Она рассчитывается по самому частотному слову, как квадратный корень из количества его вхождений. Другие сервисы проверки используют подобный алгоритм, поэтому их «тошноту» можно приравнять к показателю «классическая тошнота» на Адвего.
Определенные нормы по классической тошноте в описании анализатора не указаны. Создатели лишь рассказали, что она зависит от длины текста — например, для статьи длиной в 20 000 символов тошнота 5% нормальная, а для заметки в 1 000 символов — слишком высокая. Многие агентства и SEO-специалисты придерживаются мнения, что тошнота не должна быть выше 4-6%.
Академическая тошнота текста
Она определяется как соотношение самых частотных и значимых слов ко всему тексту. Саму формулу подсчета не раскрывают.
В описании указано, что нормальный процент академической тошноты — 5-15%. Это косвенно подтверждено самим Яндексом: в его блоге привели пример переоптимизированного текста, и академическая тошнота этой заметки составила 19%. На практике многие SEO-специалисты требуют писать статьи с тошнотой не больше 10%.
Семантическое ядро
Блок семантического ядра показывает самые часто встречающиеся слова в тексте. Именно они задают тематику материала. Поэтому на первом месте должны быть слова, релевантные теме — иначе поисковая система не поймет, о чем вы пишете, и понизит сайт в выдаче или вообще не будет показывать страницу по нужным ключевым словосочетаниям.
В нашем примере в семантическом ядре на первом месте стоит слово «вебинар». Понятно, что статья о вебинарах — это подтверждают следующие позиции ядра из тематических слов.
Частота слов в семантическом ядре
Этот показатель рассчитывается по самым распространенным в тексте словам. Чем выше процент — тем чаще встречается слово. Этот показатель тесно связан с процентом самой тошноты.
В описании семантического анализа Адвего нет рекомендуемых параметров. Многие SEO-специалисты и агентства требуют не превышать показатель в 3-4%. А в переоптимизированной заметке Яндекса максимальная частота слова в семантическом ядре превысила 8%.
В Istio.com также показывают семантическое ядро, а в анализаторе Miratext.ru его заменяет облако слов. Самые часто встречающиеся слова написаны крупным шрифтом. Семантический анализ Miratext.ru такжп показывает качество текста по Ципфа. Точный алгоритм анализа по Ципфа неизвестен, но его создатели утверждают, что он проверяет «естественность» текста, а нормальный показатель начинается от 50%. Проверка нашего текста на анализаторе выдала показатель в 34%. А при проверке на самом сервисе Ципфа — 77%. Поэтому на эту строчку при проверке на Miratext.ru можно не обращать внимания — цифры не совпадают.
Brand24
Brand24 – англоязычный сервис, пользующийся популярностью у 30 000 различных организаций по всему миру: он сотрудничает с такими брендами, как Panasonic, IKEA, H&M, Raiffeisen Bank. Он предоставляет данные из более чем 20 социальных сетей, новостных порталов, блогов и других интернет-площадок. С его помощью можно найти упоминания о конкурентах в указанных источниках и определить отношение клиентов к компании.
После анализа сайта пользователь получает индивидуальный отчет, включающий в себя график с количеством упоминаний о ресурсе и эмоциональными оценками. Все результаты отсортированы по разным видам источников: Facebook, Twitter, блог, форум и так далее.
Стоимость: есть бесплатная 14-дневная пробная версия, премиум-подписка начинается от $49/месяц
Официальная страница: Brand24
Как доработать текст
Если показатели вашего текста не совпадают с рекомендуемыми параметрами, его желательно доработать. Сделать это просто, и мы подготовили небольшую шпаргалку:
- Если «вода» высокая, удалите малозначимые слова и словосочетания, переформулируйте предложения так, чтобы в них встречалось меньше предлогов; если показатель низкий, разбавьте текст или не трогайте его
- Если классическая тошнота высокая, удалите несколько вхождений самого часто встречающегося слова, если низкая — добавьте вхождения ключевых слов
- Если академическая тошнота текста высокая, удалите несколько вхождений ключевых слов, если низкая — добавьте вхождения главного ключа
- Если в семантическом ядре находятся нетематические слова, добавьте в текст вхождения ключей и других тематических слов
- Если частота слов в семантическом ядре слишком высокая, удалите несколько вхождений
Не забывайте о том, что в первую очередь текст должен нравиться людям. Поэтому не стоит воспринимать семантический анализ текста как истину в последней инстанции — даже далеко не идеальные в плане SEO статьи попадают в топ. Например, в первой в выдаче по запросу «что такое инфляция» статье показатель воды по Адвего приближается к верхней планке, составляет 72,6%.
А на странице со второго места показатель академической тошноты превышает рекомендованную многими SEO-специалистами отметку в 10%, а частота слова в семантическом ядре превысила 5%.
Если текст интересный, полезный, структурированный, но немного не соответствует рекомендуемым показателям, можете оставить все как есть.
Как анализировать эффективность конечной работы
Эффективность текста в продвижении можно проверить при помощи инструментов веб-мастера. Установка счетчика «Яндекс.Метрики» позволит оценить изменение числа посетителей сайта, просмотреть карты прокрутки страницы и места кликов мышью.
В Google Analytics есть инструмент «Поведение». В разделе «Анализ посещаемости страниц» можно посмотреть детальную статистику.
Нужно обратить внимание на показатели:
- числа просмотров;
- средней продолжительности пребывания на странице;
- процент отказов.
Первые 2 параметра должны быть высокими, а последний — низким. Вкладка «Источники трафика» покажет самые эффективные каналы привлечения посетителей.
В зависимости от поведения пользователей нужно скорректировать страницу. Может потребоваться разбивка статьи на меньшие части или включение нового блока информации для более широкого освещения темы. Понять, в каком направлении работать, поможет список поисковых запросов, по которым интернет-пользователи находят сайт.
https://youtube.com/watch?v=R6Hy4fgqoyY
Нормальный показатель
Для оценки качества материала установлены общие требования.
Для спама
В таблице содержится характеристика текста в зависимости от степени заспамленности.
| Количество спама | Качество статьи |
|---|---|
| До 30% | Ключевые слова и фразы грамотно вписаны в текст (такой показатель может означать и то, что они отсутствуют) |
| 30-60% | Материал легко читается, а поисковые машины считают его релевантным. Для СЕО-оптимизированных текстов данный уровень является нормой |
| Более 60% | Контент переспамлен, воспринимается с трудом |
Для создания качественного материала необходимо соблюдать баланс между достаточным количеством ключевых слов и легкостью восприятия статьи.
Для водности
В таблице представлена характеристика общих показателей «воды» в тексте.
| «Водность» | Уровень | Рекомендации |
|---|---|---|
| До 15% | Нормальный | Можно оставить как есть |
| 15-30% | Повышенный | Желательно исправить |
| Более 30% | Критический | Обязательно «подсушить» |
Степень допустимой «водности» зависит от стиля контента. Наиболее низкий уровень характерен для узкоспециализированных текстов (технических, юридических, медицинских). При создании информационных и новостных статей допускается бóльшая «разбавка», но в пределах указанной нормы. Высокий уровень «водности» может иметь развлекательный и художественный контент.
Подбор LSI-ключей
Прежде чем приступать к написанию LSI-статьи, я ищу идею будущего поста, формирую приблизительную структуру и подбираю семантику. Для поиска идеи будущей LSI-статьи можно воспользоваться сервисом Portent. Чтобы правильно найти ключевые запросы, я использую специальные сервисы. В сети их множество, но исходя из личного опыта могу посоветовать пять удобных и простых.
2.1. Wordstat.Yandex
Бесплатный сервис от поисковой системы Яндекс. Он выводит количество ключевых слов, количество показов в месяц, при этом разбивая информацию на отдельные блоки. Для LSI-текста необходимо использовать правую колонку «Запросы, похожие на…». Эти LSI-слова и фразы дополнят ядро текста, разнообразив его возможными синонимами ключа. Левая колонка также полезна — здесь можно получить запросы из подсказок.

Результат сервиса Яндекс Вордстат по запросу «LSI»
2.2. MegaIndex
Ещё один бесплатный сервис, пользоваться которым можно без регистрации. Чтобы найти ключи в MegaIndex, следуйте простым шагам:
- В верхнем меню на главной странице выберите пункт «Приложения»;
- В открывшемся списке найдите блок «Анализ текста»;
- Укажите регион для показа (для примера я взяла Киев);
- Введите поисковый запрос в специальное окошко;
- Нажмите кнопку «Показать».
После этого MegaIndex предложит список релевантных тематике слов, которые он собрал из топ-10 поиска Яндекса. Сервис сканирует каждую из этих страниц, выбирая наиболее часто употребляемые ключевые слова. Для наглядности инструмент показывает процент LSI-вхождений, а также разбивает запросы на текст, ссылки, пассажи.
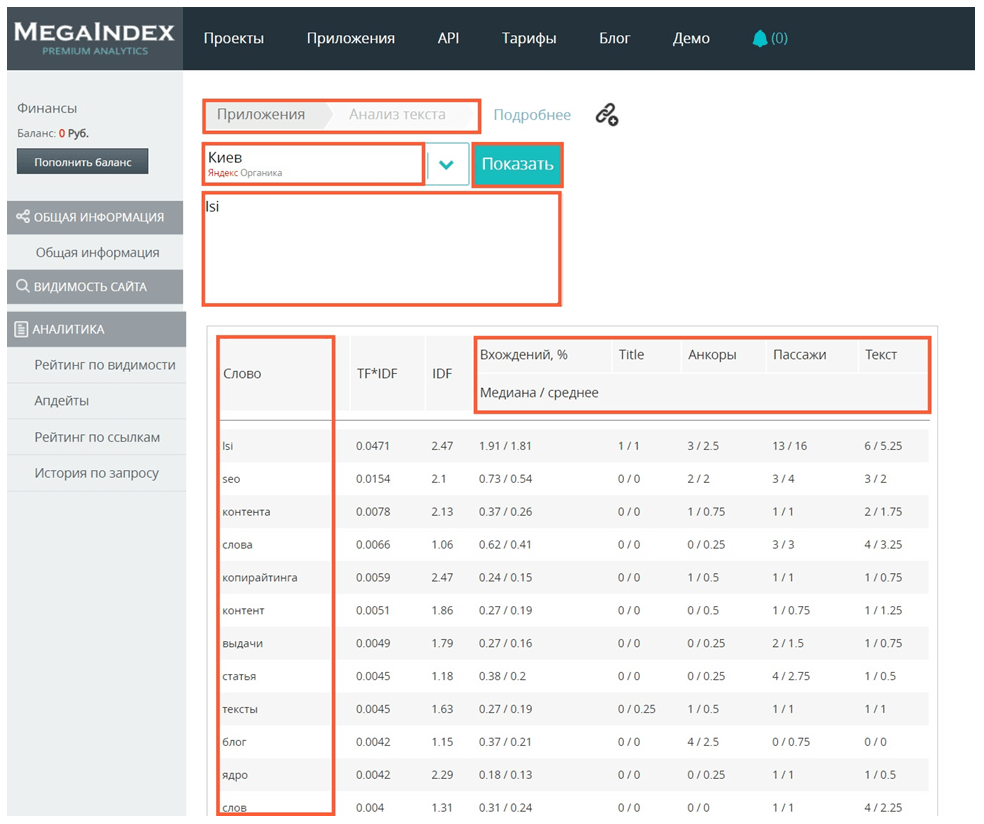
Сбор сопутствующих слов для LSI сервисом MegaIndex
Из предложенного перечня слов можно взять все, дополнив таким образом главный ключевой запрос LSI-текста, или выбирать определённые, ориентируясь на частотность, которая указана в колонке IDF. Чем ниже число IDF, тем чаще в текстах встречается слово.
В чём реальная польза:
- Сервис выдаёт все сопутствующие слова под наш ключ, которые нужно использовать в LSI-тексте.
- Делает акцент на актуальности самых популярных запросов.
- Предлагает в качестве рекомендации готовое ТЗ копирайтеру на LSI-статью.
Инструмент экономит массу времени, расширяя своей информацией данные из других источников.
2.3. Key Collector
Удобный инструмент для сбора большого LSI-ядра, который отфильтрует нужные запросы. Чтобы начать пользоваться Key Collector, вам необходимо купить лицензию и скачать программу. Настройки можно оставлять по умолчанию.
- Создайте новый проект,
- Укажите регион и поисковые системы,
- Выберите инструмент, с помощью которого будет происходить парсинг ключей. LSI-подсказки лучше всего искать через «Пакетный сбор слов из правой колонки Yandex Wordstat».
- Впишите запросы и получите результат.
Ключи выдаются уже с частотностью показов за месяц.
2.4. СловоЁб
Бесплатный аналог Key Collector. Перед началом использования программу необходимо установить на компьютер и создать «Новый проект». В настройках пропишите Яндекс-почту, затем сохраните изменения.
Для сбора ключей следуйте инструкции:
- Нажмите «Пакетный сбор поисковых подсказок» (разноцветные соты на верхней панели);
- Выберите системы для анализа;
- Введите в строке поиска «LSI»;
- Нажмите кнопку «Начать сбор».
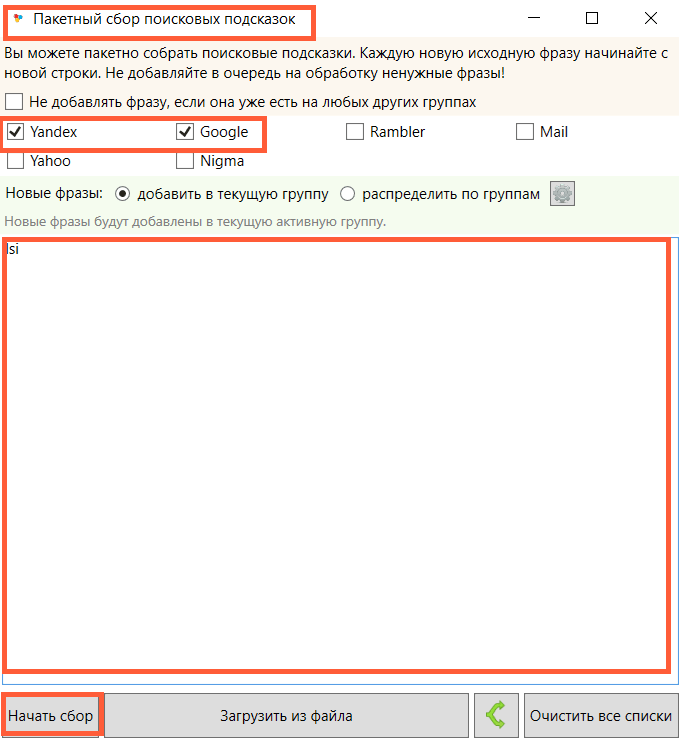
Настройки сервиса СловоЁб для сбора ключей в LSI-статью
По запросу инструмент выдал 924 результата. Сразу отфильтруйте всё лишнее, указав стоп-слова. Сделать это можно через одноимённую вкладку в меню. Когда сервис обновит собранные фразы, просто удалите помеченные строки.
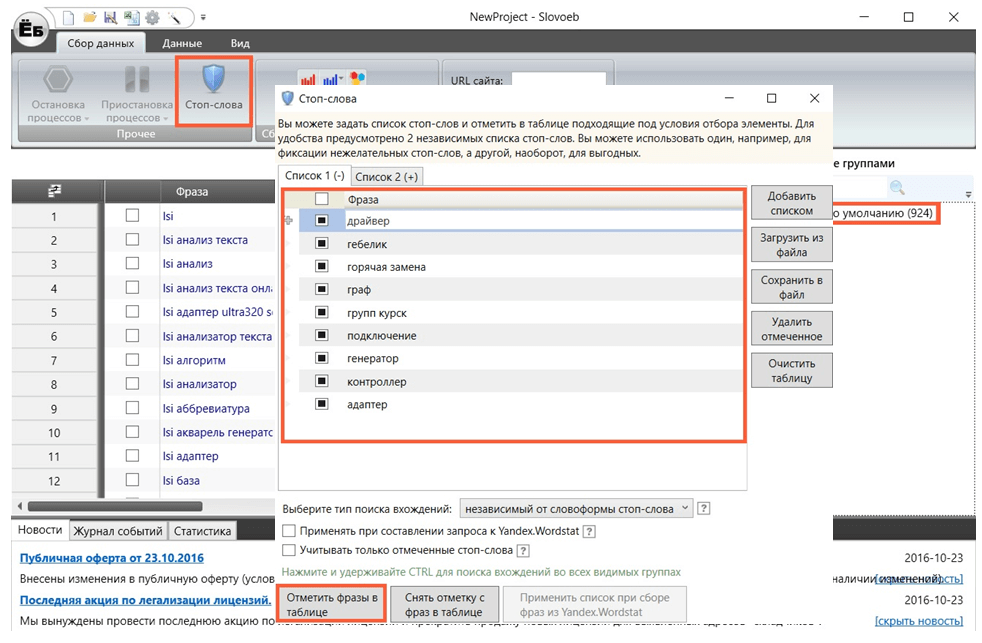
Фильтр запросов в СловоЁб через стоп-слова
Все собранные LSI-ключи из сервиса перенесите в Excel: вкладка меню → «Экспортировать данные» → выбрать папку для хранения.
2.5. Пиксель Тулс
Для работы с сервисом необходимо пройти регистрацию и выбрать нужный инструмент. Оптимальный — «Техническое задание для копирайтера». Находится в разделе «Инструменты» → «Внутренняя оптимизация».
Заполняем поля:
- Регион продвижения;
- Запрос для поиска (можно указывать сразу несколько запросов).
Нажимаем кнопку «Обработать запросы». Для LSI-статьи используем слова, задающие тематику. Они находятся в правом нижнем углу и являются хорошими подсказками для расширения главного ключа.
![]()
Подбор LSI-запросов через Пиксель Тулс
Все выше рассмотренные сервисы используются для подбора релевантных LSI-слов, которые уточняют главный ключ. Эти слова имеют прямое отношение к теме и позволяют раскрыть её максимально глубоко.
Для чего необходим семантический анализ текста?
Этот сервис необходим всем копирайтерам, которые пишут продающие статьи, рекламные статьи, а также статьи, продвигающие сайты. Семантический анализ текста поможет копирайтеру избавиться от лишних показателей, добавив необходимые.
После того, как копирайтер подвергнет свою статью семантическому анализу на бирже копирайтинга Advego – ему необходимо самостоятельно избавиться от лишнего мусора, хорошенько откорректировать готовую статью, а в завершении проверить ее на уникальность.
Знакомьтесь: игра для хорошего заработка Golden Mines:
- Наймите гномов, которые будут добывать вам руду;
- Накопленную руду отнесите на склад;
- Переработайте руду и получите за нее золото;
- Обменяйте полученное золото на реальные деньги;
Только после этого, можно сдавать статью заказчику или выставлять ее в магазины на биржах контента.